You need to read the first part of this post in order to understand this one.
I just said that there is a severe problem called Thrashing. It is as follows: Suppose, a lower priority process is executing and a higher priority process started taking the frames from it using the global allocation mechanism. This reduces the number of frames of the lower priority process and the page-fault rate increases.
When this drops below the minimum required frames, the process keeps on page-faulting for the same pages that are actively used and spends a lot of time on this rather than its execution. This situation is called as Thrashing.
This reduces the CPU utilization and increases the burden on the Paging device. To increase CPU utilization, the OS starts a new process and this again takes frames from other running processes making the things even worse.
Clearly, we have to prevent this situation. One way is that a thrashing process should not be allowed to take frames from other process. But still this process spends lot of time in the ready queue and the average service time for a page-fault increases since the queue is long.
Other way is to provide each process with minimum required frames and it should not decrease this mark. This way we can prevent thrashing but the hardest part is how to know the minimum number of frames required?
Working set Model:
The basic idea is that every process executes some sequence of routines during its execution. This means that a process uses some pages actively when executing a function which is in that pages. This is called locality of reference.
What we do is, we keep a window of some size and examine the set of pages that are being used, we count this number of pages and allocate that many frames to that process, if in future the size of this set increases we allocate more frames to this process. These frames are obtained by suspending a lower priority process which is later resumed.
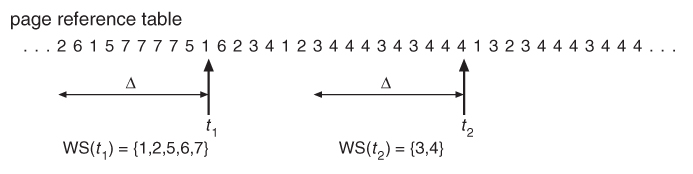
In this way, we keep the degree of multi-programming and CPU throughput higher. But the hardest part is keeping track of the window. Since it moves for every reference, it is a bit expensive to calculate the number of frames.
The other way is to check the page fault frequency. In this method, we keep a minimum and maximum value of page-fault frequency. When it falls below the minimum, it means there are more frames allocated than required. So, we take away some frames and start a new process. In the other case, we allocate new frames to the process.
In this way, unlike the previous method, there is no need to suspend a process and the overhead involved is not much.
Memory Mapped Files:
We can extend the concept of demand paging to the files also. Normally, when we open a file and perform read and write operations, they are written to the disk either synchronously or asynchronously. This involves a lot of overhead(disk accesses) and increases the execution time.
A clever approach is to bring the files data just like pages into the main memory and perform reads and writes to it, and at last when the process closes the file, it is copied on to the disk. This reduces the number of disk accesses to a large extent.
If we are interested to share the same file among different processes, we simply map the memory location of the file into the address space of the processes. It is just like Shared Memory in Unix systems.
In Linux, this operation is performed by using mmap() system call.
Memory Mapped I/O:
This technique is for the convenience of the OS. Instead of writing or reading directly from the I/O device, it just writes/reads into the buffers(technically called as registers) which are located somewhere in the main memory and sets some bit to indicate the operation.These locations are called port of that I/O device. These operations may be synchronous or asynchronous and it is up to the OS.
Allocating Kernel Memory:
Kernel memory allocation must be different from normal user-mode process memory because, first, the kernel requires data structures of different size resulting in internal fragmentation due to fixed size pages and secondly, the kernel memory must be contiguous since the hardware might not use the virtual memory service.
Buddy System:
In this method, the buddy system allocates memory in the powers of 2. Suppose, there is a contiguous allocation of 512kB, and we want to allocate 63kB, then we divide the contiguous memory by half until we can satisfy the conditions. Here we stop dividing until 64kB and allocate it.
At last, when the kernel releases memory we coalesce different parts and reclaim the memory. This suffers from internal fragmentation. If kernel needs 65kB, we still give 128kB which wastes the memory leaving the remaining 63kB unused.
Slab Allocation:
In this method, we use slabs which are usually a contiguous set of pages. There will be caches of different sizes to represent different data structures. These various sized memory locations are allocated in advance. Whenever the kernel needs an object, it just marks it as used(Of course, initially all are marked as free) and uses it. When it wants to release the memory, it just marks it as free again. No overhead of allocating/de-allocating!
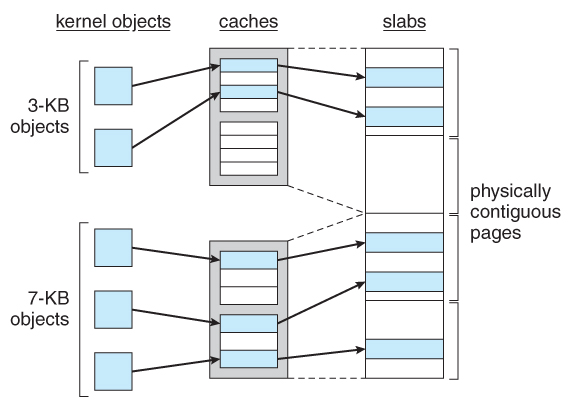
In the figure, we can see that kernel is using 2 3kB and 3 7kB objects.
These slabs may be either empty or partially filled or full. The allocating algorithm gives priority to fill the partially filled one first and then sees to fill the empty one.
As we can observe, this has advantages like no memory wastage and reduced time to allocate since the objects are allocated in advanced as said previously. Because of the various advantages, linux also uses this method.
In order to still have a better performance, we need to consider other issues which are as follows:
Prepaging:
Initially, when the process enters into the memory, there will be some continuous page faults, until it uses every page it has been allocated. The reason is that the process tries to get all the pages which have the currently executing function.(in other words, this is called Localityof Reference)
In order to avoid the above scenario, we use Prepaging. In this method, all the required pages by which the process can get its locality of reference are loaded into the main memory before the process starts( or restarts if it was previously suspended). Even when we swap-out, we need to copy these entire pages into the swap space.
This method is useful only if the pre-paged pages are used during the execution or else we can ignore this method.
Page Size:
So, let us discuss about the page size needed. What do you think? Should it be small or large? Let us see the factors effecting it.
Larger page size increases the Internal Fragmentation.
Page table size increases with decrease in page size. Hence we need to have larger page size.
Larger pages take more time for I/O operations. While smaller pages increase the total I/O that must be performed.
Larger page size reduces the number of page faults and also may include more locality of Refernces, which are not needed.
Now don't get messed up with these factors. Still it is a big question of what page size to use. But the modern operating systems are favouring larger pages itself.
I/O Interlock:
Sometimes, a process might issue an I/O request and starts to wait in the queue for that device. Meanwhile, another process might page-fault and takes the page of the former process(of course, by global replacement) to which the I/O has to occur. This makes the process messy when the I/O device tries to write to this page.
To prevent this, we associate a lock bit for each frame. Whenever, this bit is set, that page is never selected for replacement and hence the execution happens smoothly.
There are still other advantages in normal page replacement. Consider a low-priority process page-faulted and got the desired page into the memory. When it starts to wait for the CPU, a higher priority process may page-fault and it may take this newly fetched page of the former process (this page has higher probability to be replaced because both reference and modify bits are unset).
We are benifiting a high priority process at the expense of low-priority process. But the work done to fetch page previously is being wasted. To prevent this, we can use the lock bit.
This may be disadvantageous if the process doesn't clear the lock bit, because it makes the frame unusable. So, this should be carefully implemented.
Although I skipped few things, you can still refer them from here.
Can you please post the implementation of page replacement algorithms using Systems V IPC?
ReplyDelete